The first idea that came to my mind when I was developing the map was to draw a really eye-catching symbol in the central position so that it can easily be associated with the tense given. Why Superman? The initial S is a really distinctive feature of the Present Simple Tense, since it is added to the verb used with the third person singular. In particular, English-learners will often forget to add –s when they use the Present Simple. The central drawing is here to remind the visual types of learners not to forget the most specific fact concerning the grammatical form.

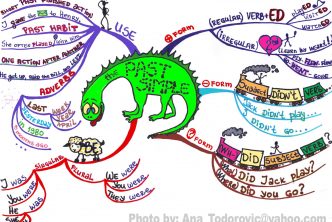
As you can see, the purple branch gives a clear illustration of the positive form of the verb given. The ant here represents plural since ants are innumerable insects.
The light blue branch gives examples of the negative verb form. So, for the negative form, auxiliary verbs do not/ does not (don’t/ doesn’t) are used. It can be noticed that the auxiliary for the third person singular contains the notorious s once again (not the main verb!). It is emphasized in the same way once again.
The light green branch gives a vivid picture of how questions are formed in the Present Simple Tense. The train engine is an optional part of a question, since it stands for wh-words. The next, obligatory carriage, shows the place of the auxiliary verb do/ does in the Present Simple Tense questions. Then comes the subject that waves at the window of the third carriage. The main verb follows.
The pink branch is booked for the smiling sheep. The verb to be is represented by a «black sheep», the one regarded as the exception by the rest. The symbol is useful here since the verb to BE is really an exception, concerning the negative and question forms, which are formed without any auxiliary forms. For negatives, only NOT is added (e.g. am not/is not/ are not), and for questions, the sheep will jump in front of the subject to make a question (inversion) (e.g. Am I? Are you? Is he?…)
Finally, the use of the Simple Present is shown in the left upper corner of the map. It is used for stating facts (e.g. The Sun rises in the East), general truths (e.g. Water freezes at 0 degrees Celsius), habits and routines (e.g. I have coffee first thing in the morning), for expressing states and emotions (Ian loves Mary)…
In addition, there are branches showing the most common adverbs used with this tense: EVERY (day, week, month, January…), always, usually, often, sometimes, seldom (rarely), never…
Now, don’t hesitate! Take your markers, color pencils and crayons and draw whatever you learn. You will absorb the new content much faster!